This is the manual for Open Ethnographer, the open source software application for ethnographic coding developed by Edgeryders OÜ.
Welcome to post any remaining questions as comments below the manual, and we will try to help. If you want to contribute to the manual, please do so at its original location. This version is just a copy that should be updated from time to time. (That also means, the original could have content that has not yet landed here.)
Content
3. Coding with Open Ethnographer
4. Managing codes, annotations and settings
6. Process for a whole coding project
- 6.1. Choosing a Discourse tag
- 6.2. Assigning the tag to an entire category
- 6.3. Assigning the tag to a single topic
- 6.4. Enabling collaborative coding
7. Best-practice conventions for coding
- 7.1. Big Picture
- 7.2. Coding Conventions
- 7.3. Codebook Structure
- 7.4. Thinking in network when coding: mapping coding to network structure
8. Archiving ethnographic data
9. Contributing to development
10. Getting ethnographic data onto the Edgeryders platform
1. Introduction
Open Ethnographer is an open source tool for Qualitative Data Analysis (QDA), which is a way to systematize and understand long chunks of text and to make sense out of it.
Usually, there are four main steps in the QDA analysis:
-
Preliminary coding. A thorough reading of the content that leads to a draft list of codes, or tags, for certain portions of text.
-
Coding. A careful reading, this time assigning a ‘code’ (a “kind of hashtag without a hash”) to a relevant portion of a given text.
-
Building categories. Group codes into categories for further analysis.
-
Analysis. The content of the categories is described with references back to the text and the original quotations.
Open Ethographer (OE) is used for coding the content of a webpage without downloading it first. It is a simple to use and intuitive tool, and the instructions are below.
There is also another, legacy version now called “Open Ethnographer for Drupal”, documented here. All relevant parts of that documentation have also been incorporated into this topic, so it is not relevant for anything anymore.
2. Getting access
To be able to use Open Ethnographer, you must be a member of the annotator Discourse user group.
To become a member of that group, visit the page of the group and click the button to apply for membership. You will be able to write a bit about why you’re applying. Then, the annotator group owners will see your request and one of them can then approve it. The owners are currently @amelia, @matthias and @alberto – if necessary, you can message them directly if you experience a problem with this process.
In addition, all administrator users of the Discourse platform automatically have access to Open Ethnographer.
3. Coding with Open Ethnographer
The basic steps are the same independent of the type of material you will be coding:
-
Log in to edgeryders.eu as normal, with an account that is a staff user (moderator or admin).
-
Visit section “User Settings” of the Open Ethnographer interface and create a user settings record for yourself. See section “Managing codes, annotations and settings” for how to do this. (This is needed before you can start coding, as a workaround for this issue.)
-
Visit the Discourse topic for which you want to see or add ethnographic coding.
-
Click on the link “Coding View” below the topic’s title. You will see a simple HTML page of the same topic, paginated in case there are many comments. For example, if the original topic URL was
https://edgeryders.eu/t/title-here/1234
then you should now be on
https://edgeryders.eu/annotator/topics/1234
3.1. Coding of text
-
To create a new annotation (“ethnographic coding”):
-
Select some text and click the annotation button that will appear.
-
Type a substring of the code’s name you want to tag with.
Multi-substring search in code names is not implemented yet, so whatever you type, including spaces, will be searched for in all code names. In practice, it works best to type starting with the first character of the code’s name but omitting all its ancestor codes, and to not omit any characters in the sequence.
-
Choose the desired code name. Either select it from the proposed completions, or type any code name that does not result in a proposed completions. In the latter case, that code will be created on-the-fly when you save this annotation.
As a special feature, it is also possible to create codes on-the-fly and sort them into the hierarchy in one step. Usually you would create codes on the first level only and later sort them into a hierarchy using the management functions. But if you want, you can also directly create them in the hierarchy by typing a code name that has
" → "(space, arrow, space) between hierarchy levels, just the way that such codes are displayed in the auto-completion proposals. -
Click “Save”.
-
-
To edit an existing annotation, hover over text with yellow background, then click the pen icon
 in the popup that will appear.
in the popup that will appear. -
To delete an existing annotation, hover over text with yellow background, then click the cross icon
 in the popup that will appear.
in the popup that will appear.
3.2. Coding of images
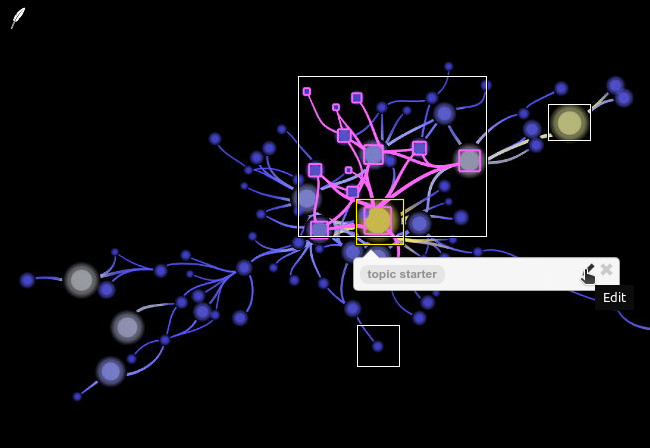
-
To create a new image annotation, pull up a rectangle around the image section you want to annotate, by clicking and dragging with the mouse pointer. Then select a code just as when coding text.
You can create as many annotations on one image as you want, and their rectangles can intersect and contain one another.
-
To edit an existing image annotation, hover over the rectangle that represents the annotation to edit, then click the pen icon
in the popover that will appear. Remove the existing code and select a new one. It is not possible to edit the size and position of the associated image selection; in that case, you’d have to delete and re-create the annotation with a different image section. -
To delete an existing image annotation, hover over the rectangle that represents the annotation to delete, then click the cross icon
in the popover that will appear.
3.3. Coding of videos
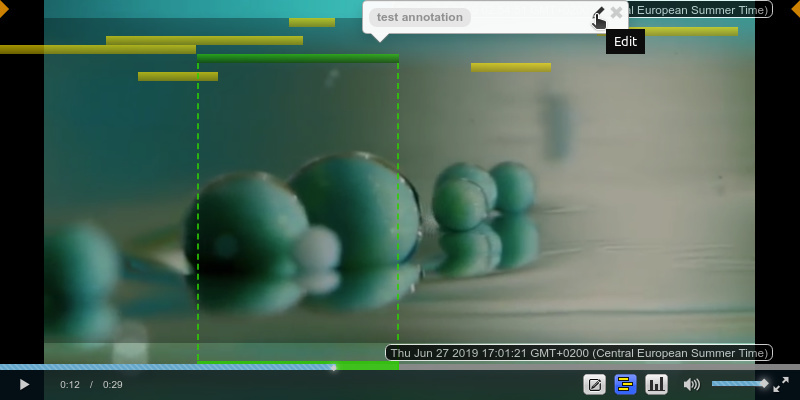
How to code a video. In the coding interface, you will see a link “See annotations / add annotations” below each video that can be coded. Click on it to go to the video coding interface, then click the top-left play button in the video to start it. Then:
-
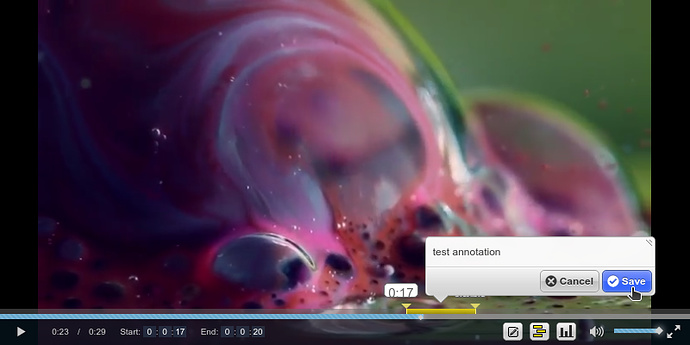
To create a new video annotation:
-
Wait for the position in the video where you want to start your annotation.
-
Click the “New Annotation” button in the player’s toolbar. The player will pause and a popover window will appear.
-
Enter a tag just as when coding text.
-
Move the yellow triangle markers to adjust start and end position of your annotation. Note that annotations in edit mode are shown in yellow, and only then the markers can be moved.
-
Click “Save”.
-
-
To view existing annotations:
-
Click on the “Show Annotations” button. Bars will appear as overlay on the video, representing annotations with their start and end times. They appear as a stack in the order they were created, with the newest at the top and one annotation per row. Timestamps in the right corners indicate the creation times of the top and bottom visible annotations.
-
Hover over the bars to see information about each annotation.
-
Click on a bar to play the part of the video to which the respective annotation belongs.
-
-
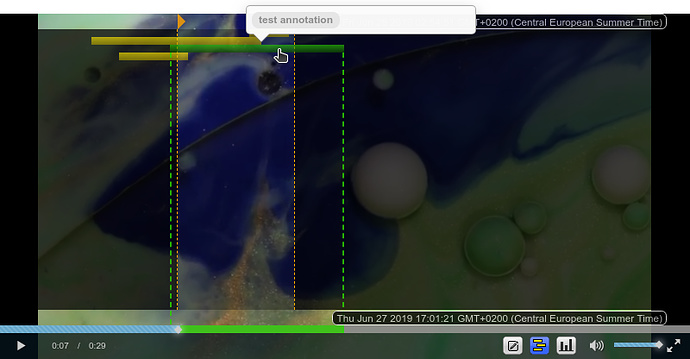
To filter existing annotations by video time range in cases where the list is otherwise too long to work with:
-
Click on the “Show Annotations” button. Again, bars represent annotations.
-
Move the orange triangles in the top left and right corners to define the time range of the video slider that should be used as a filter to show annotations.
-
Now, only the annotations that at least partially overlap with the selected time range are shown.
-
-
To edit an existing video annotation:
-
Click on the “Show Annotations” button. Bars will appear as overlay on the video, representing annotations with their start and end times.
-
Hover over the bars to show the popover window with information about the annotation.
(You can also click on one such annotation to play its associated video snippet, and then hover over the bar in its new position near the video player timeline. The same popover with information will show.)
-
Move the cursor into this popover window and click the pen icon
that will appear. -
You can now remove the annotation’s code and add a new one, and also adjust the start and end position by moving the yellow triangles.
-
Click “Save”.
-
-
To delete an existing video annotation, proceed as for editing an annotation but click on the cross icon
instead of the pen icon.
Types of videos. Videos can be added to Discourse in several ways, and the process to code them is different due to legal and technical reasons:
-
Videos uploaded to Discourse. When a user uploads a video as
.mp4file while creating a Discourse post, it will be shown in the browser’s default player embedded into the post. Such videos can be coded directly. Currently, the upload file size limit is 100 MiB to keep our backups manageable – so, choose your MP4 video quality and encoding well! -
Videos uploaded elsewhere and referenced as a file. Instead of uploading a video directly to edgeryders.eu, you can also upload it to a different platform like Imgur as long as that platform provides a direct link to the uploaded
.mp4file. When placing such a link on its own line in a Discourse post, it will result in an embedded video as well, and such a video can also be coded directly. -
Videos uploaded to video platforms. You cannot code videos embedded from YouTube, Vimeo etc… This is due to legal reasons: YouTube’s terms and conditions for example allow showing the videos from their platform only with their player, but we need a special player to create the annotations. So before a coding project can begin, an administrator would have to edit these posts and transform such videos to one of the other two types listed above. Instead of replacing the original embedded video, the administrator can also add the codeable version below, hidden inside a foldable
[details="Summary"] … [/details]element. If the video was created for the user’s post, this re-uploading will be covered by the Creative Commons licence that users grant for content they post on edgeryders.eu.
3.4. Coding of audio
Currently, coding of audio is covered by coding a video made from the audio and a still image.
At the start of a coding project, a platform admin might have to bring the audio into this format. This applies to cases where users added the audio by embedding a SoundCloud track or similar.
4. Managing codes, annotations and settings
The Open Ethnographer interface allows to administer codes, existing annotations and your user settings. Here’s how:
-
Log in to edgeryders.eu as normal, with an account that has access to Open Ethnographer.
-
Visit (and bookmark) the link to the Open Ethnographer interface:
edgeryders.eu/annotator.You have to open this link in a new tab, or copy and paste it into the URL field of your browser. It will not work when you just click on it from inside Discourse to open it in the same tab. This is due to a Discourse bug / design issue.
How to use the different sections of the interface:
-
Overview. This shows a list of the last topics coded by you, so that you can quickly pick up on your work again.
-
Codes. Here, you can create, show, edit and delete ethnographic codes and their translations to various languages.
Currently, codes form one global hierarchy, for all authors combined. After each code in the list, the number of annotations using it is shown in parentheses. To delete a code, you have to manually delete its sub-codes first, or move them to other parent codes. (This is a measure against accidentally deleting too much.)
On the screen to edit a code, you can add translations of the code’s name into other languages defined in section “Languages”.
-
Topics. A list of all topics with at least one annotation. The list can be filtered by annotation author. Clicking on a list entry will bring you to the coding view for that topic so you can continue coding there. (To start coding in a new topic, you have to use the “Coding View” link at its top.)
-
Annotations. Shows the existing annotations of all ethnographers. You can see their data, filter by creator, and change the creator (but this will only be needed during imports and other administrative changes). All other changes to annotations are done in the coding view.
-
Languages. Allows to define the set of languages that can be used in code names.
-
User settings. Allows to configure some aspects of the Open Ethnographer behavior per user:
-
Language. Set and change your standard coding language. After changing this, all codes you create afterwards will by default assume that the code name is in the language you chose here. Existing codes are not affected. (You can change the language of any existing code in section “Codes”.) If you can’t find your preferred coding language in the list, create it first in section “Languages”.
-
Discourse tag. Set or change the coding project (“ethnographic corpus”) you’re currently working on, as represented by its
ethno-*Discourse tag. It is important to keep this setting up to date, as it enables collaborative coding. When set to any
to keep this setting up to date, as it enables collaborative coding. When set to any ethno-*value, the codename auto-complete list will suggest all codes used in that coding project, independent of code author. When set to the empty value, Open Ethnographer will use the default behavior of showing a user all the user’s own codes, indepenent of coding project.
-
5. Using the API
We created an access protected custom API extension of the Discourse API that gives access to Open Ethnographer codes, annotations and ethical consent data. For the API documentation, refer to this topic:
https://edgeryders.eu/t/using-the-edgeryders-eu-apis/7904
6. Process for a whole coding project
In Edgeryders, we use Discourse tags to assign topics to Open Ethnographer projects. The presence of the project’s own tag tells the ethnographer that that particular topic is part of her project. We also use these Discourse tags to filter topics via the Open Ethnographer APIs.
This system allows easy reuse. The same topic that is relevant to today’s project could tomorrow also be used in another project. You can append as many tags as you want to the same topic, so there is no conflict.
6.1. Choosing a Discourse tag
Discourse tags that refer to ethnographic research projects with Open Ethnographer are named ethno-{projectname}, for example ethno-opencare.
You can choose the project name freely, it does not have to correspond to the name of an Edgeryders client project (as encoded in the different project-{projectname} tags).
You can also use the code codepriority to indicate to ethnographers what content you’d like coded first.
6.2. Assigning the tag to an entire category
Most Open Ethnographer projects in Edgeryders are based on Discourse categories. For example, the OpenCare category is based on several categories. To assign a project tag to an entire category, do this:
-
Navigate to the page of the category you want to monitor, for example https://edgeryders.eu/c/opencare/diy-and-open-source .
-
“Infinite scroll” to the very last topic of the category, then scroll back up. This pre-loads every topic in the category into the browser’s memory.
-
Click on the “bullet point list” icon under the name of the category, to the left of “Topic”:
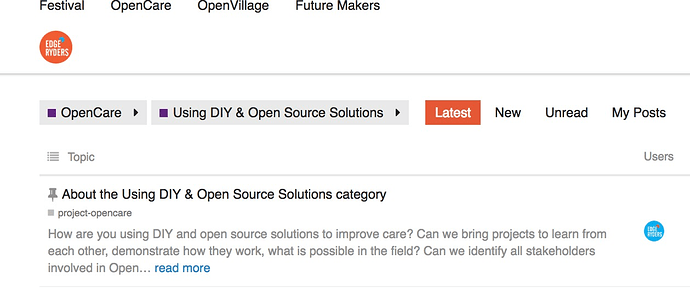
-
Two buttons appear. Click on “Select All”
-
A wrench icon appears to the extreme right of the page. Click it.
-
From the menu that appears, choose “Append Tags”
-
In the text box that appears, type the tag, for example
ethno-opencare -
Click the “Append tags” button.
If your project is based on more than one category, you will have to do this for every one of them.
6.3. Assigning the tag to a single topic
Sometimes an ethnographer or a community manager may find a topic that came out of a different project, but is happens to be relevant to the Open Ethnographer project at hand. For example, this is the case with several care-related projects coming to Edgeryders through the OpenVillage People and Projects category. To make a single topic part of the project at hand, do this:
-
Navigate to the topic page, for example this one.
-
Click on the pencil icon next to the title. A text box opens:

-
Click in the text box and start to type the project tag, for example
ethno-opencare. -
Click on the
 icon
icon
6.4. Enabling collaborative coding
Open Ethnographer needs to know that you are now working on this new coding project, so it can propose you the codes used by anyone in that coding project (and exclude any others).
For that, choose the coding project’s Discourse tag in the following Open Ethnographer user setting: User Settings → [your user] → Edit User Settings → Discourse tag”.
7. Best-practice conventions for coding
7.1. Big Picture
When we are coding, we need to think about the rigour of the coding system so that others can easily understand and use our codes and the data structure we are producing in the SSNA. This means:
- creating codes that carry meaning, are salient and are essence-capturing when viewed on their own
- defining everything in enough detail and documenting why you chose to use a specific code
- creating consistent and clear categories so that other ethnographers can easily navigate a large codebook
- thinking about how someone who has never read any of the underlying data would read and understand the code if they saw it
- thinking about what meaning the code will carry when it co-occurs with other codes in a visual network
Do code review after every coding session and clean up your codes — make sure they fit the coding conventions both technically (in terms of case, invivo designation, etc) and semantically (that they aren’t a synonym of existing codes, that they aren’t compound codes, etc). We will save ourselves a lot of headache going forward if we do this while we work instead of trying to go through 1000s of codes retroactively.
Code descriptively. When you code, don’t just code for “content”. If a machine could assign the same code as you’re assigning, that’s a good sign that you need to rethink how you’re coding. As an example of this distinction, ethnographers sometimes make the mistake of using invivo codes (where you use the same terminology as the participant) when the term itself isn’t special, rather than thinking about what they mean and finding the right code to describe that meaning, in line with the codes you and your team have used previously if the concept has come up before. See your desire to automatically assign an invivo code as a red flag going forward, and ask yourself if you’re using their exact word because it’s the word that saliently captures the concept (and the one you’ve been using thus far to capture that same concept) or because it’s the easiest thing to do in the moment. We code for meaning — what is the point of what this person is trying to say? What are they trying to get across? What values and worldview are they putting forward?
Ask yourself: if the codes I assigned to this post or comment were assembled together by themselves, would the viewer be able to tell the story of what this person is thinking or feeling? This means assigning more descriptive codes (like seeking purpose or defining justice or building inclusivity ; access and education ; complexity and asking experts ) rather than codes like limiting or involvement , which have no real meaning. This also helps you not overassign codes or create overly compound or vague codes.
Once you’ve assigned a code for a concept, be consistent and stick with it (or edit/update it across the entire corpus). The reason we call our codebook an “ontology” is that it’s more than a list of codes — it’s a compendium of participant meaning. If I call in-person human interaction face-to-face then I need to continue to use that phrase, rather than also assigning codes physical human interaction , real-life contact , and so on.
Consistency requires being consistent with the co-occurrences you use to capture when people express the same sentiment – it goes beyond not assigning single codes with the same meaning. For example, imagine participants are expressing that they want to leave something material behind that outlives them, that lasts beyond their lifetime. If I use the connection between the codes built to last and legacy , I need to not then also assign codes longevity and making one's mark or even longevity and legacy to a different story later in the month. Note that any of these combinations would be legitimate ways to capture this sentiment: you just have to pick one way of doing it and consistently apply it going forward.
7.2. Coding Conventions
Spelling and Formatting
Use British spelling for English-language codes.
Use lowercase letters (unless capitalised letter has semantic meaning, as in a proper noun).
Use accented letters as normal in all languages.
Avoid compound codes
Because the SSNA detects co-occurrences, it is important that each code carries one meaning, that can then be linked to others.
For example, code homosexuality and discrimination rather than homosexuality and discrimination or homosexuality:discrimination.
As @alberto aptly puts it:
Specificity vs Generality
If the code does not carry any real meaning on its own (e.g. approaches ), it is too general.
If the code is too granular to ever be reused (e.g. hyperactive mosquitos ) then it is likely too specific.
Sometimes this requires creative thinking. If you’re trying to capture the idea that informants are expressing that Romania is more awesome than Poland, the code Romania is more awesome than Poland is likely not going to co-occur in many places (though @noemi might disagree ![]() ) . However, we could use the code
) . However, we could use the code country comparison and co-code it with Romania and Poland (or Romania-Poland if we really felt strongly that we didn’t want to lose that specific country comparison as tied to the country comparison code, though see why we should hesitate to do this in the compound codes section above. We could always go back and copy the code Romania-Poland if we found it was too specific, assigning one instance of all the annotations to Romania and the other to Poland , so no harm done as long as we keep that more broadly useful country comparison there.)
How many codes to assign?
It is much easier to merge (and copy) codes than it is to fork them. As a result, aim for greater granularity and merge into a more general concept if you find upon review that the granularity is too small.
If we code everything discrimination and realise that we wish we’d coded homophobia and racism and sexism differently, we have to go back and re-read and recode all the annotations assigned to discrimination . If instead we code the other three and decide they are too granular, merging them all into the code discrimination is easy. If we decide homophobia is occurring on its own broadly enough but the other two are too granular, we can always merge racism and sexism into discrimination but leave homophobia alone. If we want all of the instances of homophobia to also be co-coded with the higher-level code discrimination , we can easily copy the code homophobia and merge that second instance into discrimination so that all its annotations are also coded with the code discrimination. This is what we use hierarchies for in the backend, to more easily keep track of such concepts, as I will return to in the next section.
Code ‘that which goes without saying’
Part of our job as interpretive analysts is to use our sociocultural understandings and our training to read between the lines. If community members are talking about two concepts explicitly (say remote working and e-learning ) if Covid-19 is the context from which this conversation emerges, and the community members are clearly assuming that shared context in their conversations without stating it explicitly, be sure to code it.
Culture is often termed ‘that which goes without saying’, and part of our job as ethnographers is to explicitly say it. This is especially important in the context of populism, where family values traditionalism and housing policy might be used to speak about something like homophobia in subtext.
Code only what has meaning
Back to ethnography as an interpretive method. One way not to overproliferate codes is to make sure that a code is only applied if the community member uses the concept meaningfully.
For example, if an event takes place in the United States, but the activities that happened at the event are not meaningfully connected to the fact that the event took place in the United States, in your interpretive assessment, do not apply that code. If, however, the fact that a certain activity happened in Prague (a major city) rather than a rural area, apply the code Prague . Use SSNA thinking here: a co-occurrence network around cities might differ substantially to one around a rural area (certain ideas might be more widely held and repeated in the capital city than in a rural town, for example), which we would want to capture in the SSNA. Code with intention and interpretively.
As another example, a community member might mention that they are 50 years old. You would only apply the code age if age was a meaningful frame used by the community member – if the story was about growing older and life changing, for example. But if the fact is incidental and they go on to talk about monster truck racing , do not apply the code age .
Three Tiered Invivo System
If a code is descriptive (your term for what informants are describing, or a word that is used in ordinary parlance to refer to the thing you are referring to), use unmarked text. Example: sustainability or mental health
If a code is invivo (a directly quoted word or phrase that your informants used that is unique, interesting, or salient as a concept, or does not necessarily fit the ‘normal’ use of that word) use double quotation marks. Example: "witch" , "the East", "punk"
If a code is in-between (a conceptual category used by informants that you are aggregating into a term yourself and/or that does not fit the dictionary or academic use of that term), use single quotes. Example: 'communism' or 'patriotism'
Reason:
Hierarchies
Hierarchies do not appear in the SSNA itself, but we use them to enhance our ethnographic practice. Here are some ground rules.
Every code in a hierarchy must make sense on its own. Discrimination could be the parent of homophobia or sexism , but creating a code like approaches and nesting it under discrimination is a no-go.
Use hierarchies to toggle specificity and generality.
Let’s return to an example we used above. If we want all of the instances of homophobia to also be co-coded with the higher-level code discrimination , we can easily copy the code homophobia and merge that second instance into discrimination so that all its annotations are also coded with the code discrimination. We might do this if we decide that discrimination as a code by itself would co-occur meaningfully with other codes in the SSNA.
However, we don’t want this to happen automatically, because excessively higher-level codes can end up dominating the graph too much, and may not carry enough meaning on their own to be represented (like geographical location, which is a useful organising category but not a very useful SSNA category). We use hierarchies in the backend for different purposes, and not all are worth representing in the SSNA.
7.3. Codebook Structure
The codebook consists of a code + its definition (“code description” in the backend).
You can easily edit codenames and descriptions in this view:
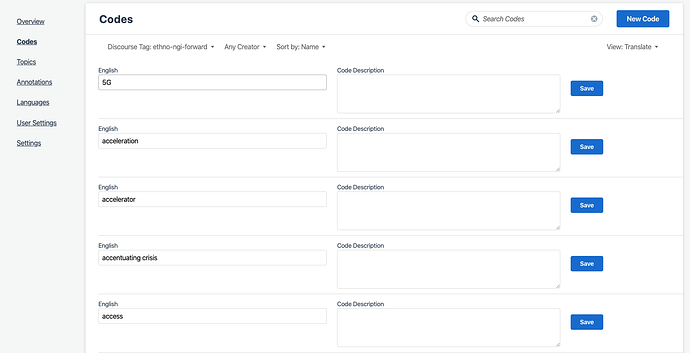
To get here, click on “Codes” and then in the “View” drop-down in the top right corner, select “Translate” (the default is “Tree”). You can filter by project tag to select your project, and you can filter by name to select codes you have assigned.
To add definitions to the codes you assigned most recently, select “Newest” in the “Sort By” Dropdown. You can also use this view to review the codes assigned most recently by other ethnographers.
For now, to do code review, we can create a Discourse thread to discuss larger changes and leave comments with our initials in the code description field itself. You can also keep any memos about the code in the code description field.
To denote that a code needs review and to call attention to other ethnographers, add a * sign at the front of the code so it appears first in the code list. When you see that asterisk, resolve the comment that the other ethnographer has left and remove the comment as well as the asterisk.
Codebook Style Guide:
- British English spelling and grammar conventions.
- Code: lowercase unless a proper noun. This is very important as codes are case sensitive!
- Definitions: initial letter is lower case unless it is a proper noun or name. Definitions end with a full stop.
- Mark in vivo terms using double quotes, mark conceptual categories (see “three-tiered system” above) in single quotes.
Document Everything
Define your codes immediately.
Define every code. I mean everything. Even if it seems self-evident. See above on saying “what goes without saying”. This applies to our own frames as well – what seems self-evident to one of us will not be self-evident to another one of us.
Assign both English and source language translations in the backend, so the codes are connected.
If you’re not sure about a term or code, note it down and explain why so that others can help you hone it / you can return and refine it. Add an asterisk so it’s clear it needs work.
Create categories in your own codebook as often as possible to help you structure and streamline your codes. I recommend creating these as you code, or at least frequently, to avoid having to do this in a big batch. Doing so makes you less likely to assign different codes to the same concept and have to merge later, since you can see your existing codes more clearly.
Interacting with Other Ethnographers’ Codes
Review other ethnographers’ codes frequently. Ideally every time you start coding, do a quick pass of what’s been added since you last checked (using the Sort by: Newest function) .
Check if:
- the code name accurately expresses the definition (is everything in the definition captured by the term used? Is there a more salient or accurate term for what the ethnographer is trying to express in the definition?)
- the code is too general to carry meaning on its own
- the code should be broken up into two separate codes
- the definition/concept is already expressed by another code used in the codebook
- the ethnographer has asked any questions that you can answer
- the hierarchies and categories they use make sense
Merging codes. If you think your code means the same thing as someone else’s (or close enough that you should seek to align them), make a note of it in the related codes tab. Once you discuss the merge with the other ethnographer, merge the codes. Remember to check with the other ethnographer if you want to change the code or its definition.
7.4. Thinking in network when coding: mapping coding to network structure
Basic concepts
When you code with Open Ethnographer, you are implicitly arranging codes in a graph. The basic graph structure is something like this:

Entities in the graph are:
- authors (participants)
- their posts
- ethnographic annotations
- ethnographic codes.
The types of relationships involved are:
- Authors write posts.
- Posts may reply to other posts.
- Annotations annotate posts.
- Annotations invoke codes.
These relationships are fundamental: we cannot deduce them from the data, only create them when authors write posts, or ethnographers code them. But there are other types of relationships that we can deduce from the fundamental ones, through a technique called projection. The most important ones are:
- A social relationship between authors: author Alice is talking to (or engaging with) author Bob when Alice writes a post that is a reply to a post written by Bob.
- A semantic relationship between codes: code C1 co-occurs with C2 when there exist two annotations A1 and A2 where A1 invokes C1, A2 invokes C2, and A1 and A2 annotate the same post.
In the case above, these relationships do not appear. There is only one author, Alice, and only one code, C1. But imagine now the ethnographers creates a second annotation on the same post, and invokes a new code C2. Like this:
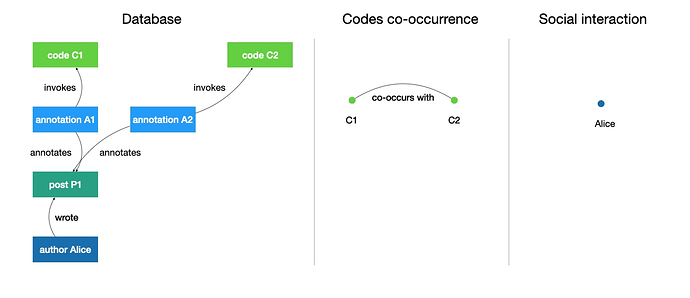
Now, the codes co-occurrence network shows that C1 and C2 co-occur once, because they are both invoked by annotations to post P1. The number of co-occurrences is represented by the weight of the co-occurrences edge. The interaction network shows only Alice, interacting with no one.
Suppose now that Alice’s post was in fact a reply to a post written by Bob. The situation is now this:
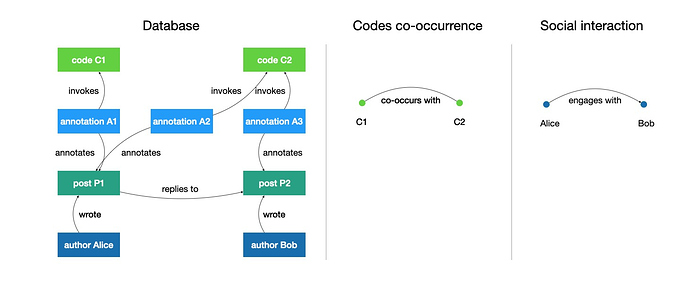
With no more annotations, the codes co-occurrence network is unchanged. But the interaction network now shows a link from Alice to Bob, symbolizing engagement. This edge, too, is weighted: the more replies Alice writes to Bob, the heavier the edge.
Every addition to the conversation database (authors writing posts, ethnographers adding annotations and codes) is encoded this way. So, you can think of coding as drawing networks. With every annotation, researchers using Open Ethnographer are adding nodes and edges to the conversation’s semantic social network, more specifically to its semantic part, the codes co-occurrence network.
Multiple annotations on a single post induce a clique
When a researcher adds an annotation to a post in OpenEthnographer, the code invoked by it will by construction co-occur with all the codes invoked by the other annotations on the same post. So, any post whose annotations invoke two or more codes gives rise to a clique of codes – a completely connected network, or part thereof. The number of edges in a clique depends on the number of nodes. In an undirected network like the codes co-occurrence network:
- With 2 annotations, you get 1 co-occurrence edge.
- With 3 annotations, you get 3 co-occurrence edges.
- With 4 annotations, you get 3 co-occurrence edges.
- With
nannotations you get(n * (n - 1)) / 2edges.
If you visualize the full co-occurrences network (including edges of weight 1), rich posts are easy to spot as very dense cliques, often connected to the rest of the graph by only one or few codes:

Interpreting repeated co-occurrences
When doing SSNA, i.e. the analysis of semantic social networks, you would not attribute a great deal of importance co-occurrence edges of weight 1. There are two reasons for this, one conceptual and one network-structural.
The conceptual reason is this. SSNA is a quest for collective intelligence. It aims to capture how a group in conversation , not a single individual or a collection thereof, see something. By construction, an edge of weight 1 in the codes co-occurrence graph means that the two codes in question occurred together in the same post only once; posts can only have one author, so only one individual has made that association explicitly, only once. This does not qualify as collective intelligence. When the same co-occurrence repeats itself across multiple posts, it is likely to encode an association supported by the collective. We treat repeated co-occurrence as a signature of collective intelligence .
The network-structural reason is that a rich post might well have 20 annotations with 20 different codes. This means 190 edges. The number of edges in the graph can easily become dominated by a few rich posts. There is no elegant solution for this.
Some network scientists dealing with interconnected cliques like to assume that all cliques (not all edges) have the same weight, equal to 1. They, then, rescale the weight of the edges by the inverse of the number of edges therein. In our case, this would mean assuming each post has one “vote” to spend. If a post is annotated invoking four codes, each of its 4 * 3 / 2 = 6 edges would have weight 1/6. A post with only two codes invoked would give rise to a single edge of weight 1, and so on.
We do not consider this to be a good solution for online ethnography. A large number of annotations on a post tends to mean that that post is indeed very rich in meaning (and often longer than average). It is by no means clear that the connections across these codes would be of less value than those stemming from posts with only 2 or 3 codes.
Instead, we filter out all one-off connections, and consider only the co-occurrences that appear at least twice in the corpus. This:
- Anchors more firmly our claim that the codes co-occurrence network has something to do with collective intelligence.
- Gets rid of the cliques.
- Simplifies dramatically the graph: in our studies so far one-off co-occurrences make up about 90% of all co-occurrences.
The discussion on this Ethnographic Coding Wiki is treated in its own topic:
https://edgeryders.eu/t/ethnographic-coding-wiki/13975/3
8. Archiving ethnographic data
For properly archiving the results of online ethnographic research, Open Ethnographer data have to be transformed, packed together with relevant metadata and uploaded somewhere “safe”.
While we don’t have this content fully developed and documented, here are some pointers to documentation about how this is being handled in our past and current projects involving Open Ethnographer:
-
Keeping POPREBEL stuff in order: a thread on where to store things, and why. The closest to a manual section so far. Requires access permissions.
9. Contributing to development
Open Ethnographer is open source software and you’re welcome to contribute:
-
Code. The code is hosted as project edgeryders/annotator_store-gem on Github. (The repo name is legacy and will change soon; it comes from an unmaintained project that we forked and used as our base software.)
-
Documentation. This document that you’re reading now is the documentation. It is provided as a wiki and you can edit it after opening an account on edgeryders.eu.
-
Issue tracker. Please contribute issue reports and feature requests in the project’s issue tracker on Github.
-
Discussion forum. If you have a feature request or idea but are not too sure about it and want to gather others’ input about it first, you’re welcome to do so in the Software (SSNA) forum category of our Discourse forum.
-
Support forum. If you need help with the installation or usage of Open Ethnographer, please post on the Open Ethnographer Manual topic of our Discourse forum – that is, simply comment below.
9.1. Vocabulary for issue reports and feature requests
Open Ethnographer: the software as a whole used for coding.
Coding View: the view in Open Ethnographer where you assign codes to text by highlighting sentences, accessed by clicking the “Coding View” link at the top of any post.
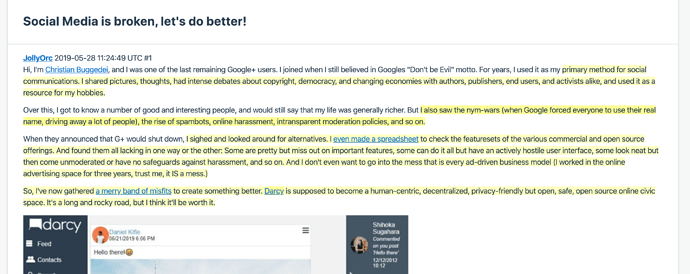
Codebook: List of codes in the backend. Can be viewed as a list of codes/ tree, which shows the codenames and hierarchies:
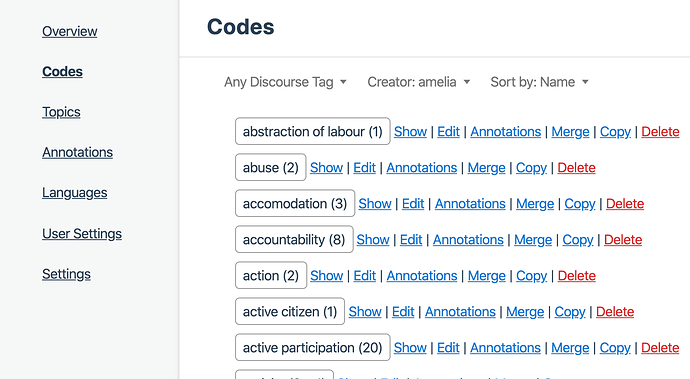
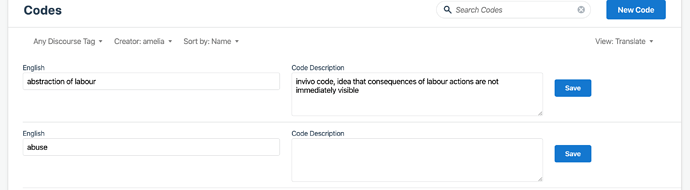
or as a translate view which shows the codes and their definitions as editable:
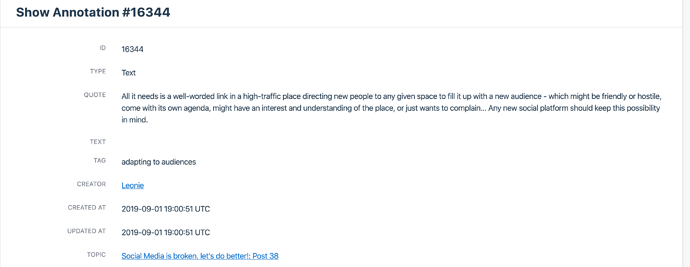
Annotation: A snipped of text that has a code assigned to it.
Thread: The original post on Edgeryders plus all the comments on it (thread title is called the Topic)
Post is the original conversation-starting contribution, comments are the user replies to this post and to other comments. Note that Discourse treats these two the same for the purposes of the SSNA.
Discourse tag: The tag (assigned at the top of any thread) that indicates what category the thread is in. E.g. "ethno-ngi-forward
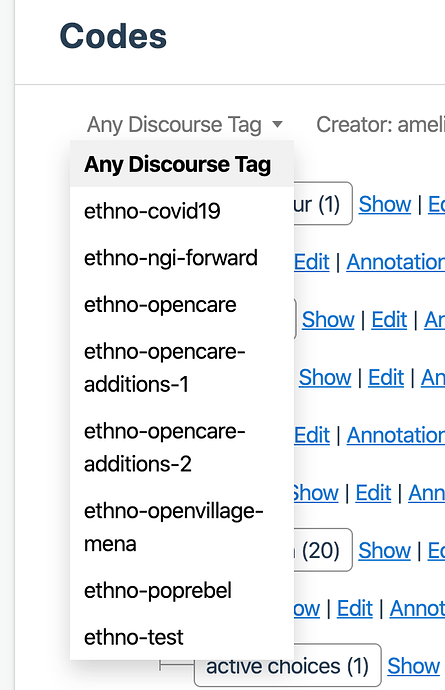
Code suggestions list: the list of codes that appears while you are coding in the coding view as possible suggestions to assign to text:

Addendum: to make a code look like this in a post on Edgeryders, use a ` on either side of the word (usually found under the F1 key).
10. Getting ethnographic data onto the Edgeryders platform
There is an ideal process for eliciting contributions from community members (as posts and comments on the platform) so they can be coded by ethnographers and show up accurately in the SSNA. They are listed below in order from most to least ideal.
-
Community member makes account on Edgeryders and posts their own story or comment under their own pseudonym.
-
Someone creates an account for the community member and posts their story or comment on platform, with their permission.
-
Another community member posts the story or comment using their own account but makes clear that these are another community members’ views.
For audio-recorded events and interviews:
(See the Consent Process Manual for the ethical framework)
-
Each participant of the event creates an account and posts their inputs as comments (difficult, but ideal).
-
ER member transcribes the audio event, creates different accounts to represent each speaker (with permission, and pseudonymised), and posts their contributions as separate contributions.
-
ER member transcribes the audio event and ethnographers code that transcription. If possible, separate into different comments based upon topic (so it’s not just one giant block of text).
-
Ethnographer codes the event audio directly using the audio coding function described in Sections 3.3 and 3.4. This is not ideal unless the event is audiovisual and the visual elements are themselves significant (e.g. there is action going on besides just speakers talking, and that action is meaningful ethnographically).
For field notes and event notes:
-
As much as possible, have participants themselves write their reflections on the platform by making an account and writing a post.
-
Import ethnographer field notes as different posts and comments attached to pseudonym accounts based on different participants’ contributions/reflections, to capture them as different people for SSNA.
-
ER member (community manager, ethnographer) posts field and/or event notes to platform in text form so they can be coded.